%3Bfill-rule%3Anonzero%3B%22%2F%3E%0A%20%20%20%20%20%20%20%20%3Cpath%20d%3D%22M866.358%2C252.528L866.358%2C47.472L815.958%2C47.472L815.958%2C207.6L729.846%2C207.6L729.846%2C252.528L866.358%2C252.528Z%22%20style%3D%22fill%3Argb(3%2C98%2C176)%3Bfill-rule%3Anonzero%3B%22%2F%3E%0A%20%20%20%20%20%20%20%20%3Cpath%20d%3D%22M657.875%2C252.528L621.587%2C176.208L604.595%2C176.208L604.595%2C252.528L554.195%2C252.528L554.195%2C47.472L635.411%2C47.472C646.739%2C47.472%20656.771%2C49.344%20665.507%2C53.088C674.243%2C56.832%20681.587%2C61.776%20687.539%2C67.92C693.491%2C74.064%20697.955%2C81.072%20700.931%2C88.944C703.907%2C96.816%20705.395%2C104.976%20705.395%2C113.424C705.395%2C120.336%20704.435%2C126.672%20702.515%2C132.432C700.595%2C138.192%20698.051%2C143.28%20694.883%2C147.696C691.715%2C152.112%20688.115%2C155.904%20684.083%2C159.072C680.051%2C162.24%20676.019%2C164.88%20671.987%2C166.992L716.339%2C252.528L657.875%2C252.528ZM654.995%2C113.424C654.995%2C108.048%20653.075%2C103.248%20649.235%2C99.024C645.395%2C94.8%20640.019%2C92.688%20633.107%2C92.688L604.595%2C92.688L604.595%2C134.16L633.107%2C134.16C640.019%2C134.16%20645.395%2C132.048%20649.235%2C127.824C653.075%2C123.6%20654.995%2C118.8%20654.995%2C113.424Z%22%20style%3D%22fill%3Argb(3%2C98%2C176)%3Bfill-rule%3Anonzero%3B%22%2F%3E%0A%20%20%20%20%3C%2Fg%3E%0A%20%20%20%20%3Cg%3E%0A%20%20%20%20%20%20%20%20%3Cpath%20d%3D%22M456.853%2C92.4L456.853%2C252.528L406.453%2C252.528L406.453%2C92.4L356.053%2C92.4L356.053%2C47.472L507.253%2C47.472L507.253%2C92.4L456.853%2C92.4Z%22%20style%3D%22fill%3Argb(230%2C51%2C124)%3Bfill-rule%3Anonzero%3B%22%2F%3E%0A%20%20%20%20%20%20%20%20%3Cpath%20d%3D%22M241.799%2C252.528L278.087%2C176.208L295.079%2C176.208L295.079%2C252.528L345.479%2C252.528L345.479%2C47.472L264.263%2C47.472C252.935%2C47.472%20242.903%2C49.344%20234.167%2C53.088C225.431%2C56.832%20218.087%2C61.776%20212.135%2C67.92C206.183%2C74.064%20201.719%2C81.072%20198.743%2C88.944C195.767%2C96.816%20194.279%2C104.976%20194.279%2C113.424C194.279%2C120.336%20195.239%2C126.672%20197.159%2C132.432C199.079%2C138.192%20201.623%2C143.28%20204.791%2C147.696C207.959%2C152.112%20211.559%2C155.904%20215.591%2C159.072C219.623%2C162.24%20223.655%2C164.88%20227.687%2C166.992L183.335%2C252.528L241.799%2C252.528ZM244.679%2C113.424C244.679%2C108.048%20246.599%2C103.248%20250.439%2C99.024C254.279%2C94.8%20259.655%2C92.688%20266.567%2C92.688L295.079%2C92.688L295.079%2C134.16L266.567%2C134.16C259.655%2C134.16%20254.279%2C132.048%20250.439%2C127.824C246.599%2C123.6%20244.679%2C118.8%20244.679%2C113.424Z%22%20style%3D%22fill%3Argb(230%2C51%2C124)%3Bfill-rule%3Anonzero%3B%22%2F%3E%0A%20%20%20%20%20%20%20%20%3Cpath%20d%3D%22M37.292%2C252.528L37.292%2C47.472L87.692%2C47.472L87.692%2C207.6L173.804%2C207.6L173.804%2C252.528L37.292%2C252.528Z%22%20style%3D%22fill%3Argb(230%2C51%2C124)%3Bfill-rule%3Anonzero%3B%22%2F%3E%0A%20%20%20%20%3C%2Fg%3E%0A%20%20%20%20%3Cpath%20d%3D%22M512.143%2C273.84L468.367%2C273.84L550.447%2C26.16L594.223%2C26.16L512.143%2C273.84Z%22%20style%3D%22fill%3Awhite%3Bfill-rule%3Anonzero%3B%22%2F%3E%0A%3C%2Fsvg%3E%0A)
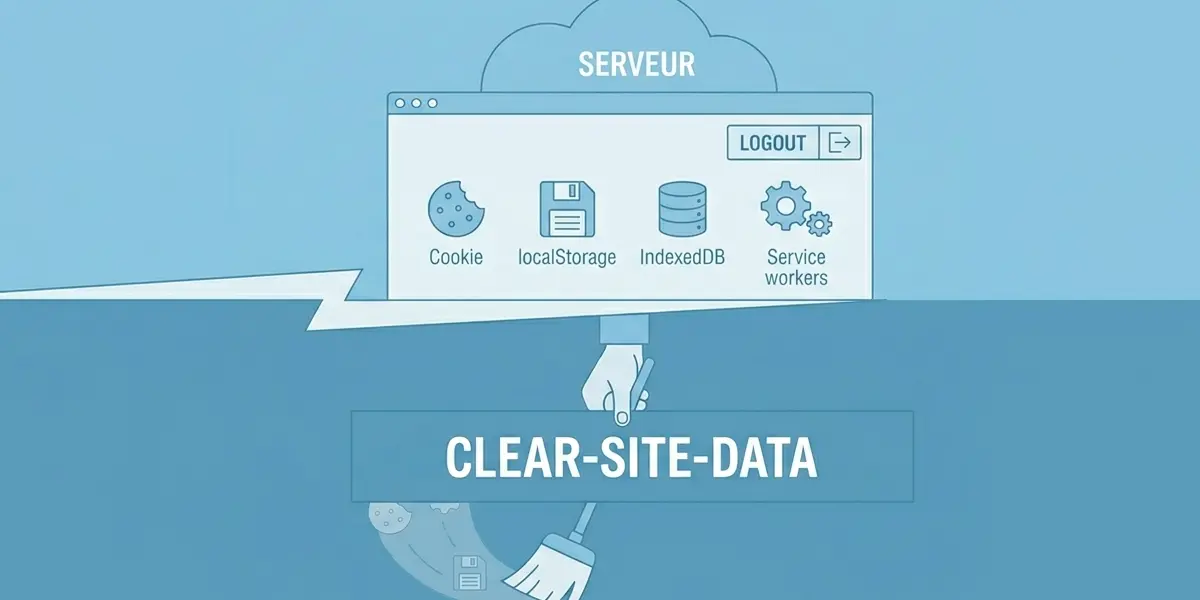
Cookies, localStorage, IndexedDB, service workers, cache offline, les navigateurs modernes conservent énormément d’état côté client. Le problème est que ces données survivent parfois bien après un logout, un déploiement ou même un incident de sécurité. Peu connu mais extrêmement utile, l’en-tête HTTP Clear-Site-Data permet enfin au serveur de demander explicitement un nettoyage du navigateur.
Introduction
Le navigateur moderne stocke plus de choses que ce que l’on peut penser : cookies, localStorage, sessionStorage, IndexedDB, cache HTTP, service workers, cache offline de PWA,… même des applications web relativement simples peuvent aujourd’hui conserver une quantité importante d’état côté client.
Pendant longtemps, les données persistantes dans le navigateur étaient liées aux sessions en cours et au mécanisme d’authentification. Mais les applications modernes peuvent continuer à fonctionner partiellement avec des données locales persistantes :
- interface encore chargée depuis le cache,
- données utilisateur toujours présentes en IndexedDB,
- service worker obsolète,
- ancien frontend encore actif après un déploiement,
- contenu compromis toujours servi localement malgré une correction serveur.
Dans certains cas, le navigateur devient presque une seconde couche applicative difficile à réinitialiser proprement. C’est précisément le rôle de l’en-tête HTTP Clear-Site-Data. Peu connu et assez peu utilisé, mais extrêmement puissant, ce header HTTP permet au serveur de demander explicitement au navigateur de supprimer certaines données locales associées au site.
Exemple simple :
Clear-Site-Data: "cache", "cookies", "storage"Avec une seule réponse HTTP, le serveur peut demander :
- la suppression des cookies,
- le nettoyage du cache,
- l’effacement des stockages locaux du navigateur.
Le mécanisme est particulièrement utile dans des contextes modernes :
- applications SPA,
- backoffices sensibles,
- PWA,
- incidents de sécurité,
- migrations frontend,
- déploiements cassants,
- systèmes d’authentification complexes.
Et pourtant, la plupart des projets web ne l’utilisent jamais.
1. Clear-Site-Data, de quoi parle-t-on ?
Clear-Site-Data est, donc, un en-tête HTTP standardisé permettant à un serveur de demander explicitement au navigateur de supprimer certaines données locales liées au site courant.
Le fonctionnement est relativement simple :
- le navigateur reçoit la réponse HTTP,
- il lit le header
Clear-Site-Data, - il déclenche la suppression des données demandées.
Contrairement à une simple invalidation de session côté backend, le mécanisme agit directement sur les données persistées dans le navigateur. Cela inclut potentiellement :
- les cookies,
- le cache HTTP,
- le localStorage,
- IndexedDB,
- certains contextes d’exécution,
- les données liées aux service workers.
Le header est défini par le W3C et supporté par la majorité des navigateurs modernes basés sur Chromium ainsi que Firefox (moteur Gecko). Safari (moteur WebKit) reste historiquement plus limité sur certains comportements, ce qui impose généralement de tester les usages critiques avant mise en production.
Le point important à comprendre est que Clear-Site-Data ne “vide pas juste le cache”. Il agit comme une demande explicite de remise à zéro partielle ou totale des données locales associées à une origine. Dans un web moderne où les applications stockent de nombreux états côté client, cela change complètement la logique de nettoyage.
Avant :
- le serveur supprimait la session,
- le navigateur rechargeait une page propre.
Aujourd’hui :
- une application peut continuer à fonctionner avec des données locales persistantes,
- même après expiration ou suppression du cookie principal.
C’est précisément ce que Clear-Site-Data tente de résoudre.
2. Ce que le header peut réellement supprimer
Le comportement exact dépend des navigateurs, mais Clear-Site-Data permet théoriquement de cibler plusieurs types de stockage locaux.
Les directives les plus utilisées sont les suivantes.
”cache”
Supprime le cache HTTP associé au site.
Exemple :
Clear-Site-Data: "cache"Cela force le navigateur à retélécharger : fichiers CSS, JavaScript, images et toutes ressources mises en cache. Très utile après :
- un déploiement qui a cassé la mise en page,
- une mauvaise configuration CDN,
- un incident de cache,
- une compromission frontend.
”cookies”
Supprime les cookies associés au domaine.
Exemple :
Clear-Site-Data: "cookies"Cela inclut généralement :
- cookies de session,
- cookies persistants,
- certains cookies de sous-domaines.
Pratique pour :
- logout plus sécurisé,
- invalidation massive de session,
- rotation d’authentification.
”storage”
Supprime les stockages modernes du navigateur.
Exemple :
Clear-Site-Data: "storage"Cela peut inclure :
- localStorage,
- sessionStorage,
- IndexedDB,
- WebSQL,
- caches liés aux service workers.
C’est souvent la directive la plus importante dans les applications modernes. Beaucoup de frameworks frontend stockent aujourd’hui :
- tokens,
- états applicatifs,
- données utilisateur,
- caches API,
- files offline,
- préférences locales.
Supprimer uniquement les cookies ne suffit alors plus.
”executionContexts”
Force le rechargement des contextes d’exécution.
Exemple :
Clear-Site-Data: "executionContexts"Cette directive est moins utilisée mais peut aider à :
- recharger certains onglets,
- éviter des états JS incohérents,
- réinitialiser des contextes actifs.
”*”
Effacement total, de toutes les données persistantes dans le navigateur.
Exemple :
Clear-Site-Data: "*"Le navigateur tente alors de supprimer toutes les catégories supportées. C’est l’équivalent d’un reset brutal côté client.
Très utile dans certains cas :
- incident de sécurité,
- malware frontend,
- service worker compromis,
- corruption applicative importante.
Mais c’est aussi la directive la plus destructive et donc à manier avec prudence.
Le point important est que ce header agit côté navigateur, et non côté backend. Le serveur ne “supprime” pas lui-même les données : il demande explicitement au client de les effacer. Cela donne enfin au backend un mécanisme standardisé pour nettoyer un environnement navigateur devenu extrêmement persistant.
3. Comment gérer les données fantômes ?
Nous l’avons vu, le web moderne stocke énormément d’état côté client. Et souvent, cet état survit beaucoup plus longtemps que prévu. Dans des architectures classiques serveur-rendu, un refresh suffisait généralement à repartir d’un état propre : nouvelle session / nouveau HTML / cache relativement simple. Avec les SPA, les PWA et les frameworks frontend modernes, la situation est devenue beaucoup plus complexe. Une application peut aujourd’hui continuer à fonctionner partiellement avec :
- un ancien bundle JavaScript,
- des données API mises en cache,
- un service worker obsolète,
- des informations utilisateur encore présentes en local,
- un état frontend incohérent après déploiement.
Le navigateur devient presque une seconde couche applicative autonome. Et c’est là que commencent les problèmes.
Logout incomplet
Exemple classique :
- le backend invalide correctement la session,
- le cookie disparaît,
- mais le frontend conserve encore :
- un token,
- des données utilisateur,
- des réponses API,
- des préférences locales.
Résultat :
- interface incohérente,
- données visibles quelques secondes,
- comportements “semi-connectés”,
- erreurs difficiles à reproduire.
Service workers zombies
Les PWA peuvent aggraver la situation. Un service worker peut continuer à servir :
- un ancien frontend,
- des assets périmés,
- des réponses mises en cache,
- une logique applicative obsolète.
Même après un déploiement corrigé côté serveur.
Dans certains cas extrêmes : le serveur est sain, mais le navigateur continue d’exécuter une ancienne version locale.
Incidents sécurité et SEO
Cas particulièrement problématique sur certains sites compromis.
Exemple :
- JavaScript malveillant mis en cache,
- payload injecté dans un service worker,
- contenu SEO parasite encore présent localement,
- ancien bundle compromis toujours servi au navigateur.
Le serveur peut être nettoyé, mais le client continue temporairement à exécuter des données locales contaminées. C’est un angle souvent sous-estimé dans les incidents WordPress ou frontend.
Le navigateur n’est plus “stateless”
Historiquement, le navigateur était surtout un client léger. Aujourd’hui, il agit souvent comme :
- une mini base de données,
- un moteur de cache avancé,
- une couche applicative offline,
- un runtime applicatif persistant.
Le problème est que beaucoup de stacks modernes accumulent les mécanismes de persistance, sans vraie stratégie de nettoyage.
Et c’est précisément pour cela que Clear-Site-Data devient intéressant :
il redonne enfin au serveur un moyen standardisé de demander un reset complet du contexte navigateur.
4. Cas d’usage vraiment utiles
Sur le papier, Clear-Site-Data semble assez simple. En pratique, le header devient particulièrement intéressant dans des situations où le navigateur conserve un état local difficile à maîtriser. Et ces cas sont de plus en plus fréquents.
Logout sécurisé
C’est probablement l’usage le plus évident. Dans beaucoup d’applications modernes, un logout ne consiste plus seulement à invalider une session serveur. Le frontend peut encore conserver :
- des données utilisateur,
- un cache API,
- des tokens secondaires,
- des informations stockées en local.
Exemple :
Clear-Site-Data: "cookies", "storage"Cela permet de forcer :
- la suppression des cookies,
- le nettoyage des stockages locaux,
- un retour à un état réellement déconnecté.
Particulièrement utile pour :
- backoffices,
- SaaS,
- outils internes,
- interfaces manipulant des données sensibles.
Reset après migration frontend
Cas fréquent avec les SPA modernes.
Exemple :
- nouvelle structure IndexedDB,
- changement majeur d’API,
- modification du système d’auth,
- refonte frontend importante.
Sans nettoyage, certains utilisateurs peuvent conserver :
- un ancien cache,
- des données incompatibles,
- un état frontend cassé.
Résultat :
- bugs aléatoires,
- comportements impossibles à reproduire,
- erreurs “uniquement chez certains utilisateurs”.
Un reset ponctuel via :
Clear-Site-Data: "cache", "storage"peut éviter beaucoup de problèmes après un gros déploiement.
Désinstallation ou refonte de PWA
Les Progressive Web Apps compliquent fortement la gestion du cache navigateur. Même après suppression côté serveur :
- le service worker peut survivre,
- des assets offline peuvent rester présents,
- l’application peut continuer à charger une ancienne version.
Dans certains cas, une PWA devient presque “persistante” côté client.
Utiliser :
Clear-Site-Data: "storage", "executionContexts"permet alors de :
- nettoyer les stockages locaux,
- réinitialiser certains contextes,
- forcer un retour à une version propre.
Très utile lors :
- d’un abandon de PWA,
- d’une refonte technique,
- d’un changement important d’architecture frontend.
Incident sécurité ou malware frontend
C’est probablement l’usage le plus sous-estimé. Après une compromission :
- le serveur peut être nettoyé,
- mais le navigateur continue parfois à servir :
- des scripts compromis,
- un ancien cache,
- un service worker malveillant,
- du contenu parasite.
Dans certains incidents SEO ou WordPress compromis, cela peut provoquer :
- des comportements incohérents,
- des faux positifs après nettoyage,
- des traces persistantes côté utilisateur.
Dans ce contexte, un :
Clear-Site-Data: "*"agit comme un reset brutal du contexte navigateur.
C’est particulièrement utile après :
- une infection frontend,
- une compromission SEO,
- une mauvaise configuration de cache,
- un incident CDN.
Applications multi-comptes ou contextes sensibles
Autre cas intéressant :
- applications administratives,
- comptes partagés,
- environnements professionnels,
- postes mutualisés.
Le header peut aider à éviter :
- fuite de données entre sessions,
- résidus applicatifs,
- reconnexions involontaires,
- état utilisateur persistant après logout.
Le navigateur moderne garde énormément d’informations. Dans certains contextes, les nettoyer explicitement devient presque une exigence de sécurité.
5. Pourquoi presque personne ne l’utilise ?
Malgré son utilité, Clear-Site-Data reste très peu utilisé dans les projets web classiques. Même dans des applications modernes manipulant énormément de stockage navigateur.
Plusieurs raisons expliquent cela.
Header peu connu
Beaucoup de développeurs n’en ont simplement jamais entendu parler. Les discussions autour : des cookies, du cache, des service workers, des SPA, du stockage offline,
sont fréquentes. Mais Clear-Site-Data apparaît rarement dans :
- les documentations framework,
- les tutoriels,
- les stacks par défaut,
- les guides sécurité.
Le mécanisme reste relativement peu documenté.
Les frameworks parlent surtout d’authentification serveur
La majorité des stacks backend continuent à raisonner principalement autour : de la session, du cookie, du token. Le modèle implicite reste souvent :
- supprimer le cookie,
- rediriger,
- considérer l’utilisateur déconnecté.
Mais ce modèle correspond de moins en moins au fonctionnement réel des applications modernes. Aujourd’hui, une grande partie de l’état applicatif peut survivre côté navigateur.
Les applications frontend accumulent du stockage partout
Les frameworks modernes rendent très simple le stockage local mais le problème est que peu de projets définissent réellement :
- quoi nettoyer,
- quand nettoyer,
- comment invalider proprement les données.
Le web moderne adore accumuler de la persistance, mais peu d’acteurs parle de nettoyage.
Les développeurs ont peur de casser l’expérience utilisateur
Crainte légitime car Clear-Site-Data peut être assez brutal :
- perte de session,
- invalidation de cache,
- déconnexion globale,
- suppression offline,
- rechargement d’assets.
Utilisé agressivement, le header peut :
- dégrader les performances,
- casser des comportements attendus,
- frustrer les utilisateurs.
Résultat : beaucoup d’équipes préfèrent éviter complètement le sujet.
Les bugs liés au stockage local sont difficiles à reproduire
C’est probablement l’une des raisons principales. Les problèmes liés : au cache, aux service workers, à IndexedDB, aux états frontend persistants, sont souvent :
- intermittents,
- dépendants du navigateur,
- difficiles à reproduire,
- spécifiques à certains utilisateurs.
Du coup, les équipes corrigent fréquemment les symptômes, sans remettre en cause la persistance locale elle-même.
Le navigateur moderne devient de plus en plus complexe
Le paradoxe est assez intéressant. Les applications web modernes cherchent :
- plus d’offline,
- plus de performance,
- plus de persistance,
- plus de résilience locale.
Mais plus cette logique progresse, plus il devient difficile de revenir à un état propre. Et pourtant, très peu de stacks intègrent réellement une stratégie claire de “reset navigateur”.
En bref
Le navigateur moderne n’est plus un simple client léger qui affiche des bonnes pages HTML avec des GIF. Entre : caches multiples, service workers, IndexedDB, mécanismes offline, frameworks frontend persistants, une application web peut aujourd’hui conserver énormément d’état local, parfois bien au-delà de ce que les développeurs imaginent réellement.
Et c’est précisément ce qui rend certains bugs si difficiles à comprendre :
- utilisateurs “semi-connectés”,
- anciennes versions frontend encore actives,
- caches impossibles à invalider proprement,
- données fantômes,
- comportements incohérents après déploiement,
- résidus après incident sécurité.
Dans ce contexte, Clear-Site-Data apparaît comme un outil assez précieux : un mécanisme standardisé permettant enfin au serveur de demander explicitement un nettoyage du contexte navigateur.
Mais attention, le header n’est évidemment pas magique. Utilisé brutalement, sans plan d’anticipation, il peut :
- casser l’expérience utilisateur,
- supprimer des données utiles,
- dégrader les performances,
- rendre certaines applications offline inutilisables temporairement.
Mais bien utilisé, il devient un vrai outil d’hygiène applicative moderne. Et surtout, il rappelle quelque chose d’assez fondamental : le web moderne sait très bien stocker des données partout mais beaucoup moins bien les nettoyer et les oublier.
Ressources utiles
Documentation MDN
Documentation de référence sur le header Clear-Site-Data :
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Clear-Site-Data
Spécification W3C
Spécification officielle du mécanisme : https://www.w3.org/TR/clear-site-data/
Compatibilité navigateurs
Vue d’ensemble du support navigateur : https://caniuse.com/mdn-http_headers_clear-site-data
Debug service workers
Très utile pour comprendre les comportements persistants côté navigateur :
Chrome DevTools : Application, Storage, Service Workers, Clear storage Documentation : https://developer.chrome.com/docs/devtools/storage/
Tester le header rapidement
Exemple curl :
curl -I https://example.comOu via les outils réseau navigateur :
- onglet Network,
- inspection des Response Headers.